业务逻辑¶
Moose 提供了一系列的动作(action)支撑我们的日常工作,其中最常使用的就是上传 upload 和导出 export 了。这一节中我们着重解释这两类任务背后的工作原理,以期帮助大家理解在诸多的upload和export类中共通的流程。
上传(upload)¶
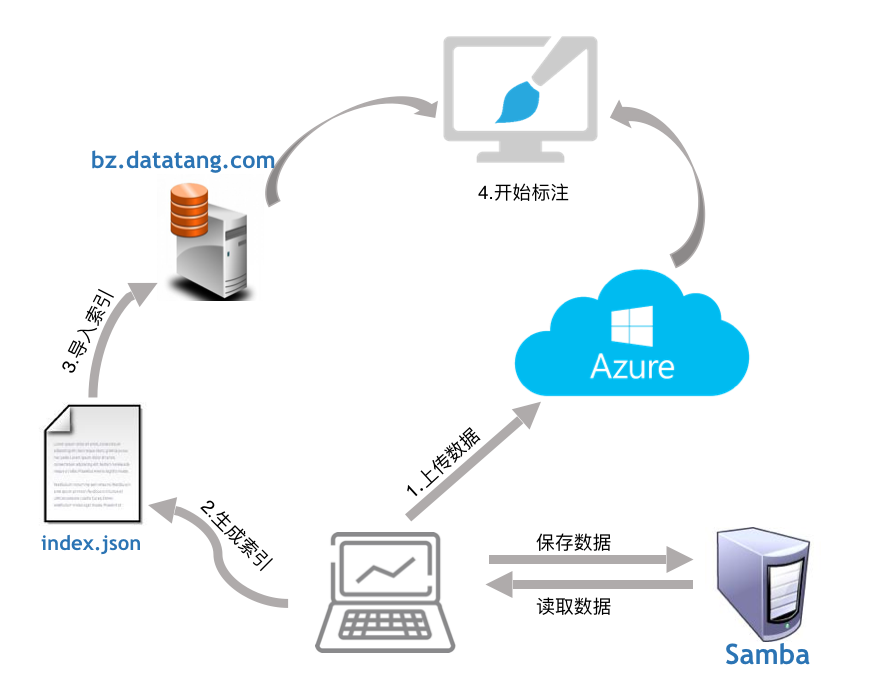
如上图所示,上传过程包含以下步骤:
- 将想要标注的文件由本地上传到 Azure Blob Storage 。微软官方提供了教程解释如何使用 blob ,其中除了 Python SDK 外,还包括了一系列其他的方法。我们对此进行了封装,并提供了 连接(Connection) 模块帮助用户通过几行代码完成上传;
- 将已上传的文件列表按照标注模板需要的格式进行组织,形成索引文件。索引文件提供了被标注对象的相关信息——如存储路径、文件标题、音频内容、音频时长等;
- 利用平台的接口导入索引文件。后台通过解析索引文件,在数据库中插入相关信息;
- 标注人员开始标注。这一过程将会首先从后台提取相应信息,前端页面解析后加载并从 blob 中提取原始文件。
需要注意的是,为了方便处理,我们定义了一套惯例:针对每一期任务都有一个唯一的 task ID ,这个 task ID 既对应着标注平台上手动创建的一期任务,也对应着后台MongoDB中存储该期索引和标注信息的一个 database 的名称 ,同时也是 blob 中存储该期标注文件的容器名。
因此索引文件中,如果我们只记录文件在容器中的名称(意即 myblob 而非 http://myaccount.blob.core.chinacloudapi.cn/mycontainer/myblob 这样的完整的地址),系统会自动使用对应 task ID 的账号和容器来扩展url。
导出(export)¶
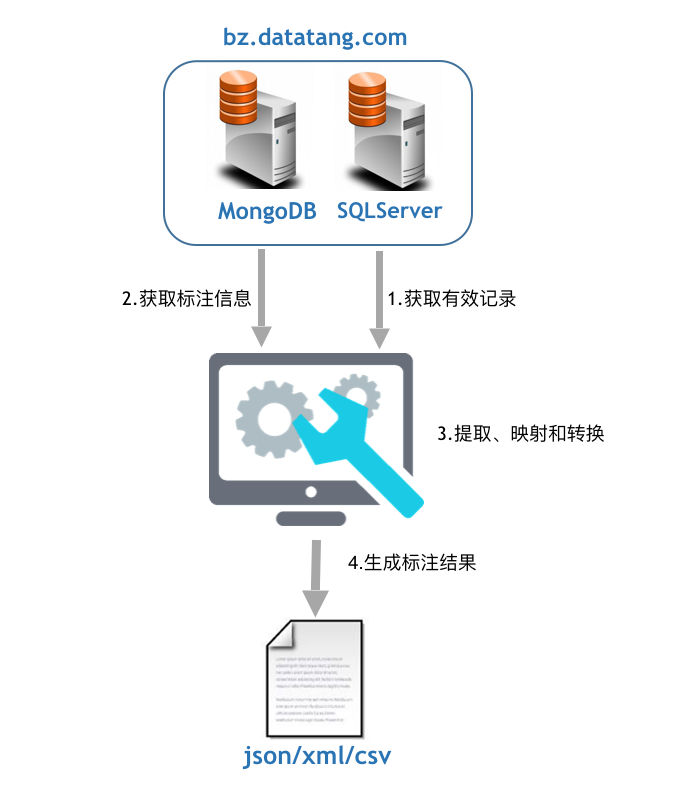
如上图所示,导出过程包含以下步骤:
- 从后端的 SQL Server 数据库中提取对应的
task ID符合条件的记录。其中,每条原始数据和其标注结果都分别对应着一个guid,分别称为SourceGuid和DataGuid,; - 从后端的 MongoDB 中提取对应的
task ID所有的索引和标注数据。注意,此时的索引和标注数据分别是两个 collection (名称分别为source和result),他们各自间的记录还没有建立一一对应的关系; - 通过提取到的
SourceGuid和DataGuid,将source和result的记录建立一一对应的关系,并提供给数据工程师进行后续的数据提取、映射和转换等处理; - 将结果生成文本文件。
我们可以发现,将 SQL Server 和 MongoDB 中的数据联系起来的是每条记录的 guid 。其中 SQL Server 主要用于存储结构化的信息,诸如数据的导入时间、标注时间、标注人员等,而 MongoDB 则用于存储非结构化的数据,如标注文件的地址和名称、标注对象的标签和坐标点。因此我们主要利用 SQL Server 筛选(通过强大的 where 表达式)提取出符合记录的 guid ,再在 MongoDB 中提取该 guid 对应的原始信息(通过索引文件导入)和标注信息,再进行后续的加工和处理。